Why it is important that transaction do not commit on failed master in a MySQL HA cluster
In this article we will look into a very important concept of distributed computing and that is we need to prevent happening of transaction on failed master in a HA cluster of MySQL, being other nodes has elected a new master (earlier slave) due to Network partitioning.
Here we will assume the setup of HA cluster as follows:
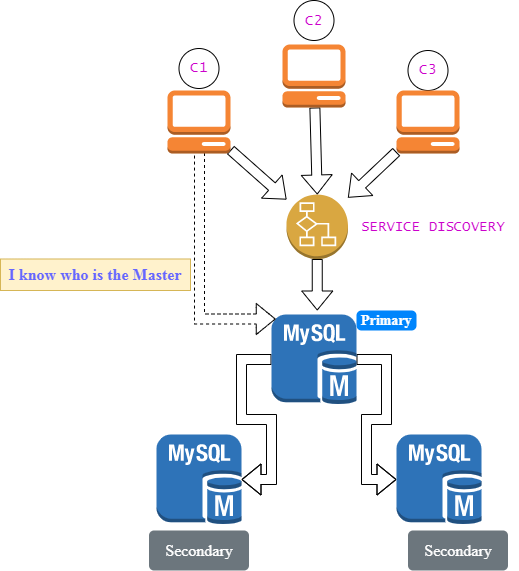
Client/s first connect to Service Discovery module to know the current Master, they cache the information for a specific interval. They then talk to the Master to proceed their transaction/s. The transaction are then replicated to connected replicas.
The client who has the Master information will cache it and do not change it until told to do so.
We will tell you, what will happen if we allow transactions on a failed master, using a real world use case, and so you will know why it is important to prevent it.
The setup is as follows:
- 3 Clients.
- 1 Service Discovery Module.
- 3 MySQL server, 1 Master/Primary and 2 Replicas/Secondary.
Please see the diagram representation below: STATE A
Now assume that there is a network partition between the Master and the 2 Replicas. The replicas with a common consent (quorum) choose a Master between them and lets say update the information in the Service Discovery module.
But our Client (C1) has still the information of old master and connected to it. Now since transaction are allowed on old master, hence C1 can execute transaction on it and can create inconsistency in HA cluster data state because that transaction never reaches the new HA cluster.
Please see the diagram representation below: STATE B

Let us understand this with a real world example:
A customer Manoj is going to order a phone from an online shopping company. He is attached to master and is our client C1, but now before he can complete the transaction, network partition happen and the cluster comes in state 2. Hence later on it is possible that his order never shipped (because the order fulfillment team is fetching data from new cluster state) nor able to see in the database, but might be possible that Manoj has got a success message and even money cut from the bank.
SOLUTION
- Stop application to write on a failed master like by using MySQL semi synchronous replication.
- Logging of important Application event in a fail safe manner like Kafka cluster or MongoDB Replica set/Cluster.
I personally believe that you should implement both the methods for better visibility and consistency, if time and project's cost let you do that.
Comments
Post a Comment